Is 86% Recall Good Enough?
On metrics, thresholds, and who should actually be making the call

“Prof. E, is 86% recall okay? Or do we need 90%?”
A few years ago, my research team spent weeks going in circles over a number. We were building an AI system to flag sites for structural inspection, specifically, infrastructure in areas where routine human assessment is expensive and slow. At some point, one of the scientists asked: “Prof. E, is 86% recall okay? Or do we need 90%?”
Then someone floated a hypothetical: what if we could push to 96 on the validation set? Would that be the bar?
I don’t remember resolving it in that very conversation. What I do remember is the realization that we weren’t arguing about model performance anymore. We were arguing about policy. And we hadn’t invited the right people into the room.
Before getting into what the right question actually is, let me back up, because a lot of people working with or commissioning AI systems hear “precision,” “recall,” and “F1,” and just tune out, thinking they’re only for data scientists or AI engineers to understand. That’s a problem, because understanding these technical terms is critical and carries serious consequences. They describe the mistake and identify who bears the cost.
There’s been a lot of focus on generative AI lately. Reasonably so. But most classification models running in production today do something much simpler and much higher-stakes: they sort things into two (or more) buckets. Fraud or not fraud. Flag this site for inspection or don’t. Screen this patient or let them through. The model outputs a number, a probability score, and your system converts that into a decision.
Every machine learning metric is a different way of measuring how the model performed and what kinds of mistakes it made.
The confusion matrix is the foundation. Four cells: things the model correctly flagged (true positives), things it correctly left alone (true negatives), things it missed (false negatives), and false alarms it raised (false positives).
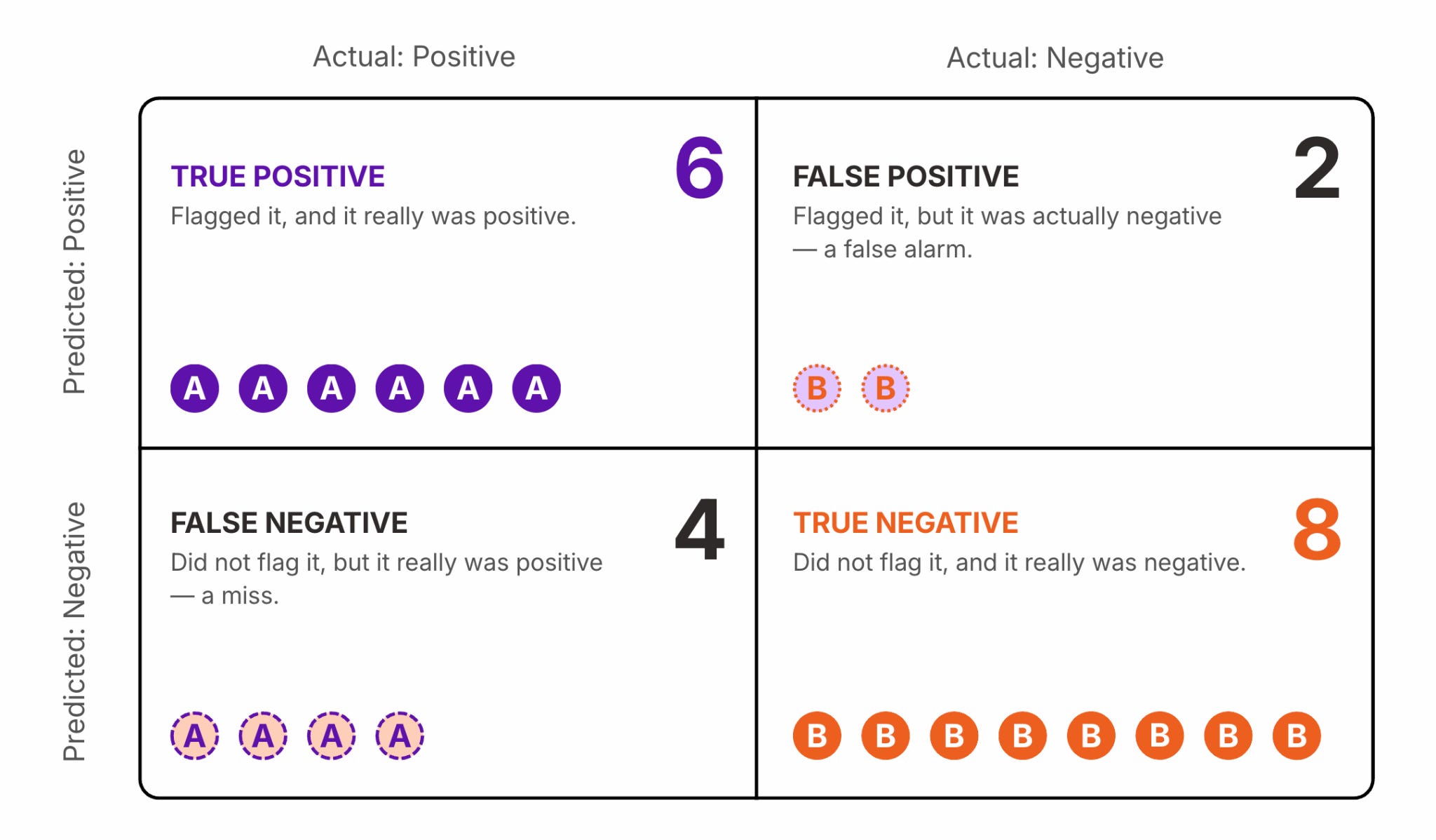
Everything else is arithmetic on top of these four numbers.
Recall asks: of all the real positives out there, how many did the model catch?
Precision asks: of everything the model flagged, how much of it was actually a positive?
Specificity asks the mirror of recall: of all the real negatives, how many did the model correctly leave alone?

They measure different things, and optimizing for one often trades off against another. I hope you can see that they are not interchangeable.
Here’s where the infrastructure project becomes useful.
In structural inspection, missing a genuinely faulty site is a very different error from flagging a site that turns out to be fine. A false negative means a defect goes uninspected. A false positive means a team gets dispatched unnecessarily. Those errors are not symmetric. They don’t land on the same people, they don’t cost the same thing, and they don’t carry the same moral weight.
Recall is the metric that tells you how many real faults you caught. The question “is 86% recall okay?” is really asking: Are we comfortable missing roughly 1 in 8 genuinely defective sites? As a data scientist, I always emphasize that this is not a data science question, but an infrastructure policy and domain question.
Good enough compared to what?
And before debating whether 86% or 90% is the right bar, there’s a prior question worth asking: good enough compared to what? A useful reference is the proportional chance criterion (PCC), which is the accuracy you’d get by randomly assigning outcomes in proportion to how often each class actually appears in your data. In structural inspection, truly defective sites are rare. If only 10% of sites in your dataset are genuinely faulty, a model that flags nothing gets 90% accuracy by doing no work. The proportional chance criterion in that case sits around 82%. A model clearing 88% may be only modestly better than random. The argument over two percentage points was already the wrong conversation, and possibly an argument about noise.
And honestly, in a thesis defense, I could just as easily ask why we are benchmarking against PCC at all. PCC assumes outcomes are assigned randomly based on class proportions, but industry inspection processes are not random systems. The more meaningful comparison may be the actual operational baseline: how inspectors currently perform, what defect rates are missed in practice, and whether the model improves on that real-world standard.
Now, when you care more bout the estimate of both kinds of errors roughly equally, then F1 is a metric you want. Data scientists reach for F1 when they want a single metric that balances precision and recall. Skipping the math, it gets pulled toward whichever of the two values is lower. Precision of 0.90 and recall of 0.30 gives you an F1 of 0.45, not 0.60. The weak side dominates.
A good example is spam detection. A false positive means a legitimate email lands in the spam folder; a false negative means spam gets through to your inbox. Neither is catastrophic. Both are annoying. You want the model to be reasonably good at both, and F1 captures that balance.
But sometimes you don’t care equally, right? That’s when the weights matter.
Take cancer screening. Missing a real case, which is a false negative, is far more costly than flagging someone who turns out to be healthy. The follow-up tests are stressful, but survivable. The missed diagnosis may not be. Here you want F2, which tilts the metric toward recall. You’re saying: catch as many true cases as possible, even if it means more false alarms.
Flip the scenario. A bank’s fraud team manually reviews every transaction the model flags. Each review costs time and labor. If the model raises too many false alarms, the team drowns, and the whole system slows down. Here you want F0.5, which tilts toward precision. You’re saying: only flag what you’re fairly confident about, because the cost of a false alarm is real.
That choice — how much to penalize each type of error — is a business decision, not a modeling one. And that brings me back to the two projects I mentioned earlier, because both of them forced exactly that conversation.
The branch-siting project was a good example of this. A client wanted a prescriptive AI platform to help decide where to open their next branch. Three to five potential sites as inputs, ranked by likelihood of success. We were a few weeks into scoping when we brought in domain experts and asked what “success” looked like.
Revenue within the first year? Foot traffic? Customer retention? Market share?
They couldn’t agree. Every expert had a working definition. None had ever been made explicit, compared against the others, or stress-tested across the edge cases. The technical problem was tractable. The prior problem—what are we actually trying to maximize?—had never been formally posed.
That is where AI governance tends to break down in practice. Not in the model. In the choices that precede and surround it.
Most classification models don’t output a hard label. They output a probability score, and you decide what probability is high enough to trigger an action. That cutoff is the threshold. The default is usually 0.5. Wherever it sits, it determines how the system distributes false positives and false negatives, and on whose behalf.
We have curves for this: the ROC curve, the PR curve, and the AUC. Each one sweeps across every possible threshold and shows you the shape of that tradeoff before you commit to a number. They deserve their own post because the math could get genuinely interesting. But the gist is this: a model that’s just guessing looks one way on these curves; a model that’s actually learning something looks very different. And the AUC collapses all of it into a single number between 0.5 and 1.0, useful for comparing models before you’ve picked a threshold. Once you deploy, though, you still have to pick one. The curves don’t do that for you.
At that point, you have to ask whether this is really a decision data scientists alone should be making for the company.
In the infrastructure project, we eventually resolved the loop by widening who was in the room. We stopped asking the data scientists to decide and brought in people with direct knowledge of the consequences. We settled on a threshold skewed toward recall, documented why, and built in a human review step for every flag.
In the branch-siting project, we ran a structured session with domain experts before touching the model, mapping each definition of success, tracing what data each would require, and forcing a decision about which combination the organization was prepared to stand behind. That process eventually led us to multiple models, each serving a different purpose and operating under a different definition of success. Reaching that point required more than technical execution; it required an intuition for the tradeoffs involved and a grounded understanding of what generalized models can and cannot realistically do. The modeling came after. The governance came first.
That sequence doesn’t feel natural to how technical teams are taught to work. It feels like delay.
But having sat on both sides, I can confidently tell you that it’s the opposite.
So. Two questions. That’s what this really comes down to.
First. What metric are you actually tracking, and does it reflect which error you’re more afraid of? Accuracy is almost never the right answer in high-stakes classification, especially when the classes are imbalanced. Know whether you need high recall, high precision, or a balance. Know whether F1, the PR curve, or something else is the right lens.
Second. Who decided on the threshold, when, and on what basis? Is that decision documented, revisable, and connected to a real accountability chain? If something goes wrong at month seven, can you reconstruct why the system was set the way it was?
A model is “good enough” when the people who understand the consequences of its errors have looked at the right metrics and agreed on a threshold they can stand behind. That conversation is harder than it sounds. But skipping it is how you end up arguing about two percentage points on a validation set, and not realizing you’re actually arguing about policy.