What the Thread Doesn’t Remember
On context windows, external memory, and the real discipline of AI-assisted development

The first thing to understand about an LLM is that it does not have memory in the way you might think it does. It behaves less like a long-term collaborator and more like a system working from temporary active memory. It can reason about whatever is currently loaded into the session, but it does not carry a durable understanding from one conversation to the next unless that context is brought back in. Each time you send a message, the model processes everything inside its context window: your conversation history, attached files, instructions, code snippets, error logs, and screenshots. All of it lives there temporarily, for the duration of that session.
The model has no persistent knowledge of your project between sessions. It knows only what you put in front of it.
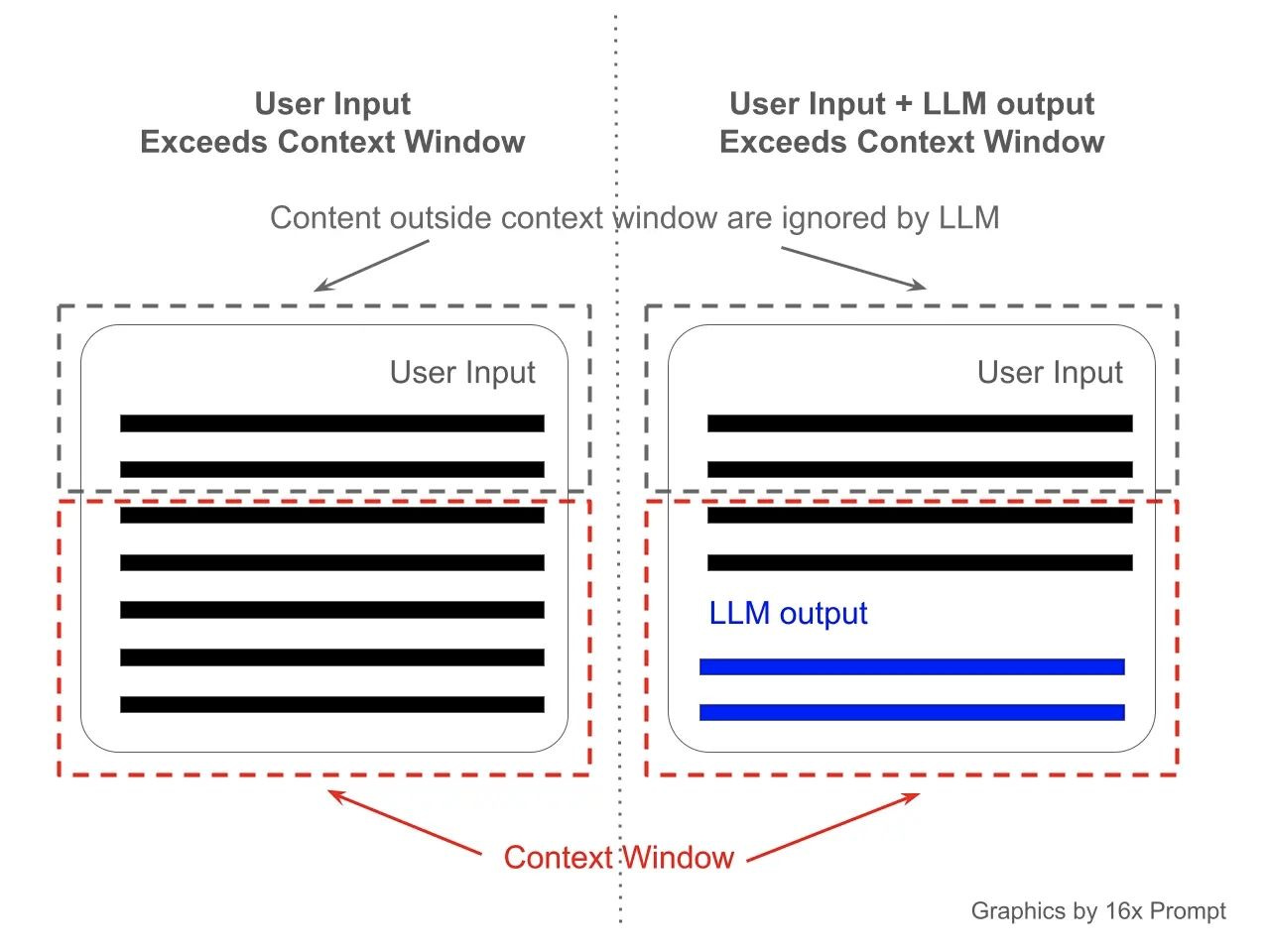
That context window is finite. Only a limited amount of information can remain active inside the session at once, and as a thread grows longer, older material competes with newer instructions for attention.
I wrote about some of this in an earlier piece, though that article focused more on the experience itself. The operational side became clearer later; I was managing a growing software project across long AI sessions that probably should have been broken into five or ten smaller threads.
When I built my first iOS app using Claude Code and ChatGPT, I had no mobile development background. Swift was new to me. I was learning the Xcode toolchain, designing the architecture, and debugging in real time while the conversation history kept expanding underneath the work.
In the early stages, this worked well. The model had a clean context: fresh requirements, a small codebase, and clear goals.
As the app grew, so did the thread. Old debugging attempts stayed in history. Abandoned approaches sat beside current ones. I had fixed a bug three ways before landing on a solution, and all three attempts were still there, in the context, potentially influencing what came next. The parameters the model had inferred early on, before I tightened the specs, remained as background assumptions.
And the model was still reading them.
The best way I’ve found to describe this is context pollution. Old instructions, deprecated code, contradictory edits, exhausted debugging paths: they do not disappear. Instead, they accumulate. The signal-to-noise ratio inside the thread degrades. When you ask the model to reason about a system that has grown more complex over time, that degraded context produces increasingly unreliable outputs.
Nothing necessarily breaks in an obvious way. My code still compiled, the interface still looked right, and the outputs still seemed plausible. But the reasoning underneath has started drifting.
I noticed this through a kind of mathematical unease. After years of building models by hand, I have developed an intuition for when outputs look plausible, but something is off. The numbers were coherent. Nothing really crashed. But the behavior still felt slightly misaligned.
I went back through the logic step by step and found that the assumptions inferred early in the session, never corrected, were still shaping the outputs. The model had been working from a version of the problem that no longer existed.
Correcting it meant more than fixing the code. It meant reconstructing context from scratch.
Managing context is the actual work
The problems that emerge from a long, polluted thread are not limited to accuracy since they compound structurally.
Unused imports accumulate. Dead code from abandoned features stays in the files, unreferenced, gradually adding noise. Local patches applied to fix immediate failures start conflicting with the global logic. Duplicated functions appear because the model, working from a degraded view of the codebase, re-solves a problem it already solved three hundred lines earlier.
The fix is not to hope the model keeps track, but to treat the context window like any limited, high-value resource: deliberately, with discipline, and with external structures that do not depend on it.
Part of the reason this became necessary was that the project itself grew very quickly.
The first version of the app was essentially a personal prototype. It only needed to support my own workflow and assumptions. Once I started using it more regularly, I began noticing things I wanted to change. Some workflows felt awkward when used repeatedly. Some features were missing entirely because I had not yet encountered the situations that required them.
Then I opened the app to family and friends through TestFlight. That changed the feedback loop almost immediately. People interacted with the app differently from how I did. They got confused in places that felt obvious to me. They requested features that never would have occurred to me because their priorities and habits were different from mine.
The project became more complex from there. More features meant more state to manage, more edge cases, more architectural decisions, and more historical context accumulating inside the development threads. At that point, the context window started behaving like a crowded room.
That forced me to become much more deliberate about context management, session boundaries, and external project memory.
I maintain a set of Markdown files that function as external memory for the project. They do not live inside any session thread. They exist in the repository alongside the code, and I paste or reference the relevant ones whenever I start a new Claude Code session.
The thread begins clean. The project state comes in through documents I control.
Here is what the directory looks like:
/project-root
├── CLAUDE.md
├── README.md
├── CHANGELOG.md
├── HANDOFF.md
├── APP_ARCHITECTURE.md
├── AUDIT_CHECKLIST.md
├── ROADMAP.md
├── /skills
│ ├── dead-code-audit.md
│ ├── cleanup-pass.md
│ ├── regression-review.md
│ ├── import-sweep.md
│ ├── deployment-checklist.md
│ └── handoff-generator.md
├── /App
├── /Views
├── /Models
├── /Services
├── /Utilities
└── /TestsAPP_ARCHITECTURE.md is a living document of the system’s structure: what each module does, how the modules relate, and what the data flow looks like. When the architecture changes, I update it. When I start a new session, I paste it in. The model sees the current architecture, not the version from four weeks ago.
Otherwise, the model reconstructs the system indirectly from the fragments visible inside the current context window. A maintained architecture document reduces the amount of structural guesswork the model has to perform. Instead of inferring how the system is organized from scattered context, the model starts from an explicit description of the current architecture, constraints, and responsibilities.
CHANGELOG.md records what has been added, changed, or removed, and when. It is useful for me, but it also gives the model a compressed, reliable view of how the codebase has evolved without needing to infer that history from the thread.
HANDOFF.md is what I always open a new session with. It is a structured summary of the project’s current state: what works, what is in progress, what is broken, what decisions have been made, and why. Writing it at the end of a session forces me to consolidate what I actually know. Pasting it at the start of the next session means the model inherits that consolidated knowledge, not a polluted thread.
AUDIT_CHECKLIST.md keeps me honest during feature development. It lists what I need to verify before treating a feature as complete: tests run, edge cases checked, imports cleaned, and no new dead code introduced.
The /skills folder is where the workflow becomes more structured.
Skills as reusable context
A Skill, in this workflow, is a Markdown file containing a structured instruction set for a specific task. It is not a script. It is a document that the model reads to understand the scope, rules, and output format of a particular operation.
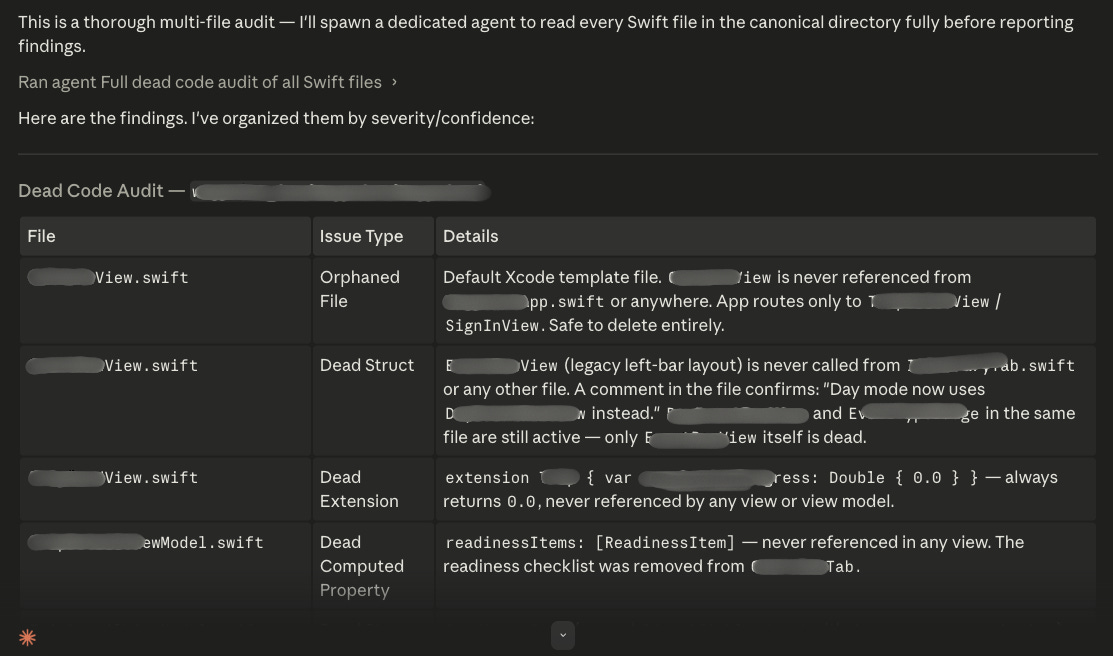
Here is what a dead-code audit Skill looks like:
# Dead Code Audit
## Objective
Identify obsolete, duplicated, deprecated, or unused code safely.
## Rules
- Do not remove code automatically.
- Present findings first.
- Explain why removal is safe.
- Categorize uncertainty separately.
## Output Format
### File
/path/to/file.swift
### Issue Type
Unused function
### Details
`fetchLegacyData()` is no longer referenced.
### Recommendation
Safe removal after verification.
### Risk
LowAnd a cleanup pass:
# Cleanup Pass
## Objective
Safely remove approved dead code incrementally.
## Rules
- Modify one file at a time.
- Show diffs before proceeding.
- Explain every deletion.
- Pause for approval after each file.
- Rebuild after major removals.Without something like this, I would be re-explaining the same constraints every session, such as do not auto-delete, show me first, one file at a time. With the Skill file, I paste it once, and the model operates inside those constraints for the duration of the session.
It also narrows the operating context intentionally. The model is not doing open-ended reasoning about the codebase. It is doing one specific, bounded task.
Skills reduce repeated prompting. They reduce token waste. They make the model’s behavior in that session more predictable.
Division of labor
By that stage, ChatGPT had become part of the workflow too, though it was serving a very different role from Claude Code.
Claude Code is the implementation environment. That is where code gets written, refactored, and debugged. The context there is focused on the codebase.
ChatGPT acts as a co-architect, reviewer, and thinking partner. When I hit a confusing error, I describe it to ChatGPT and ask it to help me reason through the likely cause before I go back into Claude Code. When I am about to make an architectural decision, I talk it through there first. When I am writing a tricky Claude Code prompt, I draft and refine it in ChatGPT.
This keeps the strategic thinking out of the implementation thread. A long reasoning session about algorithm design does not pollute the session where the code gets written. The two threads stay focused on different problems.
What I actually do, sequentially
After adding a meaningful cluster of features, I do a proper handoff. I run the dead-code audit Skill, review the findings, and approve what to remove. Then I clean one file at a time, pause for a build after every five or six meaningful changes, run an unused-import sweep, and commit to GitHub.
That sequence is not glamorous at all, but it keeps the codebase coherent as the app grows.
The build-and-commit discipline matters more than people expect. If something breaks, a recent commit means the failure is localized. I know exactly what changed. Without frequent commits, debugging becomes archaeology.
The larger point
LLMs lower the cost of generating code. They do not lower the importance of understanding what your code does or why it is structured the way it is.
The app I built is running. It does what I designed it to do. Getting there required treating the model as a capable tool inside a system I had to design and maintain.
Context management, external memory, verification loops, cleanup discipline, version control: these are the conditions under which AI-assisted development stays reliable as projects grow.
I should also say clearly: I am not sure this is the best way to do it. Hah! I got my hands dirty and found a workflow that holds. There are many articles out there on how to use these tools more effectively. Some are good. Some contradict each other. The volume can get overwhelming fast.
What I have described here is what worked for me on this project, so I would not take it as a prescription.
That said, getting your hands dirty is precisely how you learn what you do not know. You stumble into a specific problem and become much better at searching for a solution because you know what you are actually looking for. Vague curiosity produces vague results. A concrete problem produces a targeted search.
One thing worth noting for new Claude Code users: your usage across claude.ai, Claude Code, and Claude Desktop all counts toward the same usage limit. Longer conversations with heavier context consume more of that limit. This is another reason the handoff-and-fresh-session approach is useful. It keeps individual threads shorter and more focused, which is easier on both the model’s context window and your usage budget.
The broader discipline applies across most long-context LLM systems because the underlying constraint is the same: finite context windows.
The model generates. We architect, verify, and govern.
That division of responsibility has not changed. What has changed is that the tooling now makes generation fast enough that coordination becomes the bottleneck. If you do not build for it, the thread eventually becomes the problem you are solving, not the code.